NarrateAI MCP Server Demo Shows Claude Adding Voiceover to Videos

NarrateAI MCP Server Demo in Claude
A live demonstration was recorded showing the NarrateAI MCP server working inside Claude. The demo itself was narrated using NarrateAI.
How It Works
The workflow is straightforward: you type a video URL into Claude. Claude then calls the MCP tool and waits for the job to complete. The process takes 3-5 minutes, with Claude polling for status every 60 seconds. When finished, Claude returns a fully narrated video. No separate UI or manual uploading is required.
The demo revealed that Claude is capable of watching a silent screen recording, understanding what's happening in the video, and writing narration that matches the on-screen action. This effectively gives Claude voiceover capabilities.
Technical Notes
The async functionality was tested and held up as expected. The creator noted being pleasantly surprised by this result.
Connection Methods
There are three ways to connect to the NarrateAI MCP server:
- Through Claude.ai settings
- Via Cursor or VS Code using stdio
- Through Smithery
Complete setup instructions are available at narrateai.app/mcp. A free tier is included.
📖 Read the full source: r/ClaudeAI
👀 See Also

Unlocking Proactivity: A Deep Dive into Clawbot Innovations from the Community
Discover how enthusiasts are enhancing their Clawbot's proactivity through inventive strategies and community-driven insights. A look at discussions and revelations from r/openclaw.
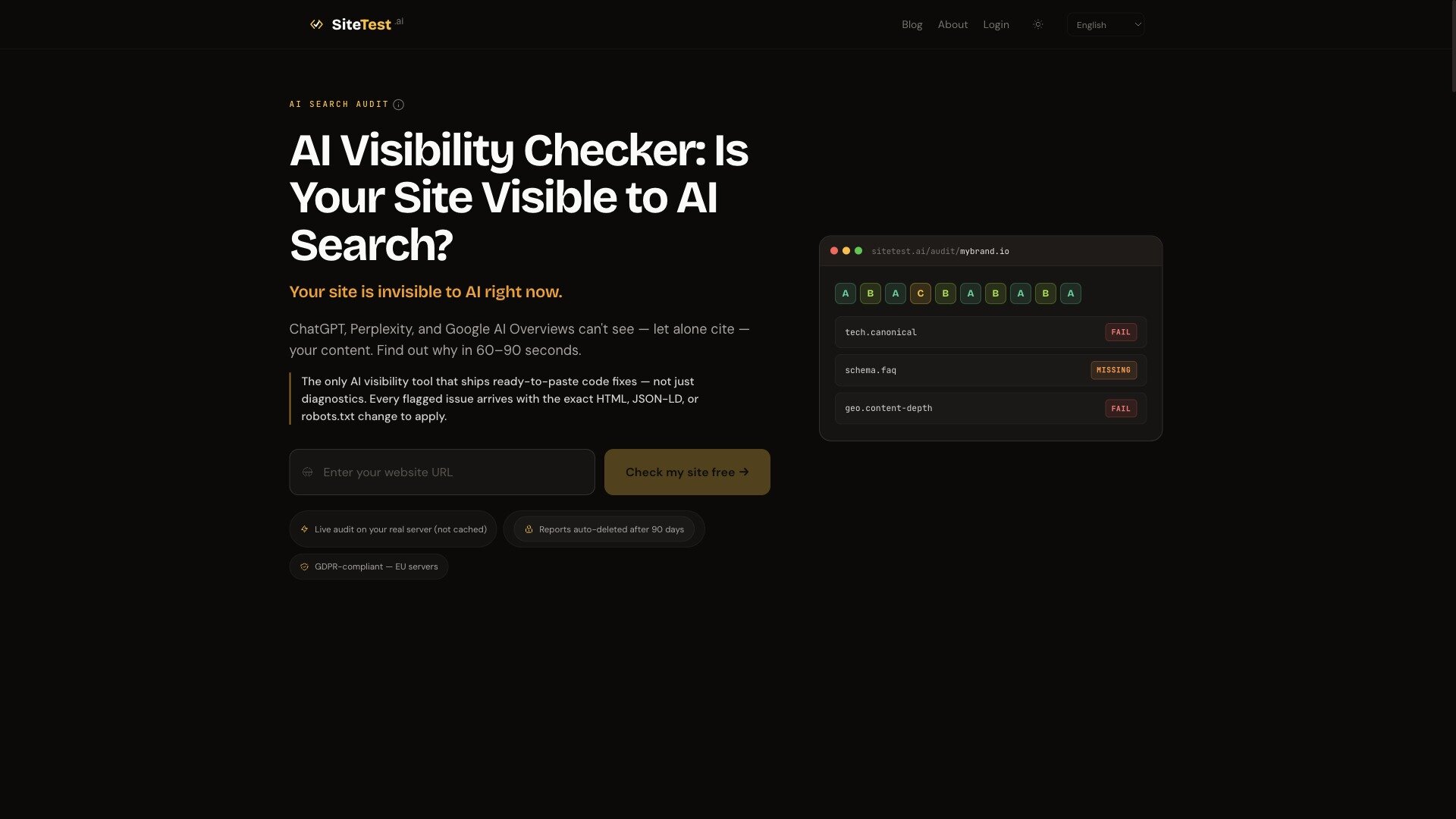
SiteTest.ai launches a free AI Visibility Checker for ChatGPT, Perplexity & Gemini
New free tool sitetest.ai runs a 168-point GEO audit, probing GPTBot, PerplexityBot and Google-Extended on your real server. Per-engine A–F grade plus copy-paste code fixes.

OpenJet v0.4: Zero-Config Local Coding Agent with llama.cpp Backend
OpenJet v0.4 is an open-source terminal coding agent for local LLMs that auto-detects hardware, configures llama.cpp, and provides a Claude Code-style workflow with no API keys.

10.33 t/s on Qwen 3.5 35B with a $300 Laptop: Full Optimization Breakdown
A developer achieves 10.33 t/s on Qwen 3.5 35B Q4_K_S on a Lenovo Ideapad Slim 3i ($300) using ik_llama.cpp, core pinning, MTP speculative decoding, and BIOS performance tuning.