Entscheidungspass: Eine Audit-Schicht für die Governance der KI-Agenten-Ausführung

Was Decision Passport adressiert
Die aktuelle Diskussion zum Quellcode-Leak von Claude Code auf r/LocalLLaMA verdeutlicht eine kritische architektonische Lücke in KI-Agenten-Systemen. Während Agenten Fähigkeiten wie Werkzeugzugriff, Browserzugriff, Speicherverwaltung, Hintergrundausführung und mehrstufige Arbeitsabläufe erlangen, verschiebt sich die Governance-Frage von "Kann der Agent nützliche Arbeit leisten?" hin zu Fragen der Rechenschaftspflicht.
Die Governance-Lücke
Die Quelle identifiziert Schlüsselfragen, die aktuelle Protokollierungs- und Beobachtungstools nicht vollständig beantworten:
- Wer hat diese Aktion autorisiert?
- Unter welcher Richtlinie?
- Welcher Ausführungskontext bestand zu diesem Zeitpunkt?
- Was hat sich geändert?
- Was wurde blockiert?
- Ob dieser Datensatz später außerhalb der ursprünglichen Laufzeitumgebung noch vertrauenswürdig ist
Der Autor merkt an: "Protokolle helfen bei der Inspektion. Nachweise helfen bei der Verteidigung."
Decision Passport Funktionen
Das Tool bietet:
- Nur-anhängbare Ausführungsprotokolle
- Portable Nachweisbündel
- Offline-Verifizierung
- Manipulationssichere Ketten
- Verifizierer-zuerst-Design
Der Autor stellt klar, dass dies nicht per se "Sandbox-Escape" oder Agentensicherheit "löst", sondern die Governance-Lücke sichtbarer macht und stärkere Antworten darauf liefert, was passiert ist, in welcher Reihenfolge, unter welcher Berechtigung, mit welchen Beweisen und ob dies später ohne Vertrauen in die ursprüngliche Plattform verifiziert werden kann.
Verfügbare Repositories
Das Projekt ist Open Source mit zwei Hauptkomponenten:
- Core:
https://github.com/brigalss-a/decision-passport-core - OpenClaw Lite:
https://github.com/brigalss-a/decision-passport-openclaw-lite
Diskussionspunkte
Die Quelle wirft Fragen auf, die die Community bedenken sollte:
- Ist dies nur bessere Beobachtbarkeit?
- Eine fehlende Audit/Nachweis-Schicht?
- Überentwickelt für die meisten Agenten-Workflows?
📖 Read the full source: r/LocalLLaMA
👀 Siehe auch
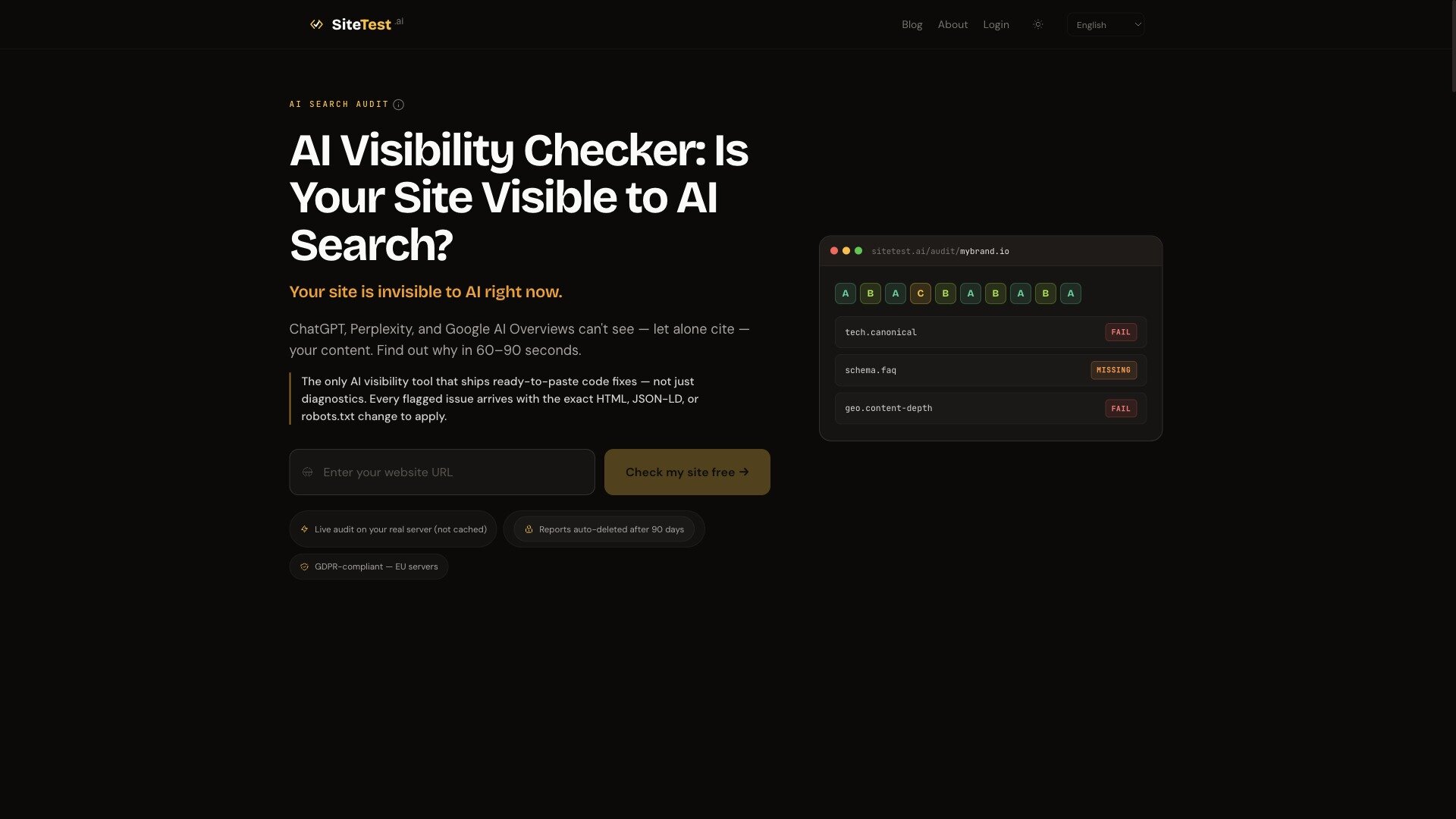
SiteTest.ai bringt einen kostenlosen AI Visibility Checker für ChatGPT, Perplexity & Gemini auf den Markt
Das neue kostenlose Tool sitetest.ai führt ein 168-Punkte-GEO-Audit durch und testet GPTBot, PerplexityBot und Google-Extended auf Ihrem echten Server. Pro Engine eine Note von A bis F sowie kopierbare Code-Fixes.

"Sitzungsspeicher-Funktion in Claude Code eingeführt"
Claude Code umfasst jetzt eine Funktion zur 'Sitzungsspeicherung', die Sitzung Zusammenfassungen in summary.md Dateien generiert und verwaltet. Schalte sie mit tweakcc für interaktive Sitzungen frei, die bestimmte Token- und Toolaufrufschwellen überschreiten.
Zillow-Full: Eine OpenClaw-Fähigkeit, die manuelle Immobilienrecherche in eine automatisierte Deal-Pipeline verwandelte
Ein Entwickler baute 'zillow-full' auf OpenClaw, um Zestimates, Steuerhistorie, Preishistorie und Vergleiche pro Immobilie abzurufen. Mit einem nächtlichen Cron-Job, der Angebote anhand von Deal-Kriterien bewertete, stiegen die Großhandelsgeschäfte von 2 auf 11 pro Monat.

Lern-Kit: Ein Claude-Code-Plugin für die Einarbeitung und Erkundung von Codebasen
Learning-kit ist ein kostenloses Claude Code-Plugin, das Repositorys analysiert, um strukturierte Lernpläne und interaktive Tutorials zu generieren. Es hilft Entwicklern, unbekannte Codebasen zu verstehen, bevor sie Änderungen vornehmen, mit konfigurierbaren Durchsetzungsmodi und Fortschrittsverfolgung.